
statduck
왜 요약통계량인가? 본문
요약통계량은 적률(Moment)이라고 볼 수 있다. 이 적률은 함수의 모양을 결정짓는 녀석이다. 이 녀석으로 어떤 함수가 지나는 점을 기준으로 모양을 추정할 수 있다(데이터 포인트->분포추정) 평균, 분산, 최빈값 이런 요약 통계량(summary statistics)들이 예시이다.
- 평균: 중심을 측정하는 척도. 선형 연산 성립
- 분산: 퍼진 정도를 측정하는 척도.
- 최빈값(mode): 쌍봉분포에서는 유니크 하지 않을 수 있다
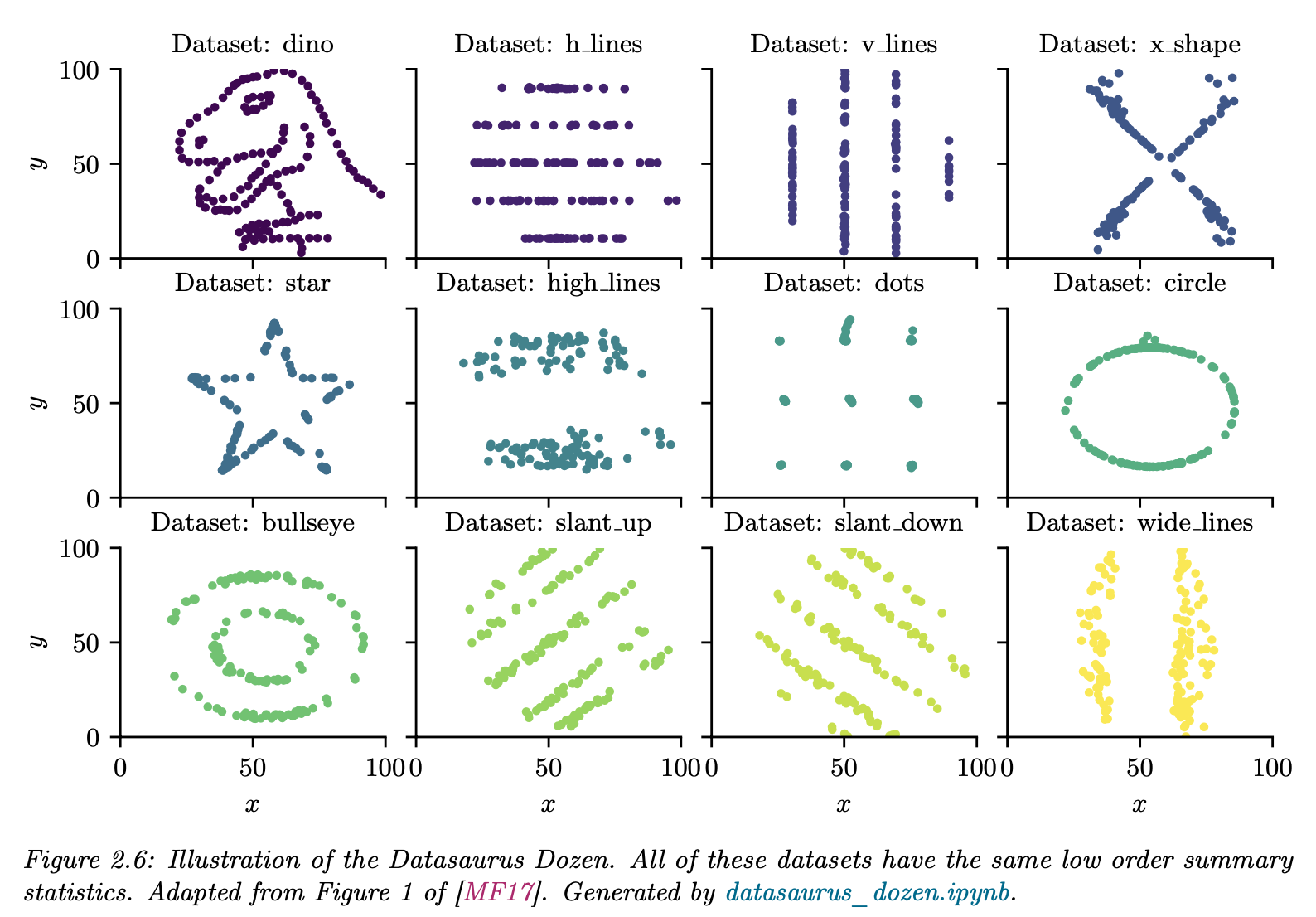
그렇지만 위 그림처럼 요약 통계량만 믿다가는 큰 코 다칠 수도 있다. 같은 요약통계량을 가지더라도 위와 같이 전혀 다른 데이터의 흐름 혹은 두 데이터의 관계를 설명하는 경우가 있기 때문이다. 1차원 데이터의 경우에는 아래처럼 박스플랏 대신 분포를 육안으로 설명해주는 바이올린플랏으로 데이터를 시각화하여 문제를 해결할 수도 있다.

바이올린 플랏은 이 때 비모수적 분포추정(Non-parametric Density Estimation)의 일종인 kde를 이용하여 시각화하는 방식이다.
(참조) https://statduck.tistory.com/19
고차원에 대해서 이런 추정을 하려면 어떻게 해야할까?: https://arxiv.org/pdf/1904.00176.pdf 해당 논문을 읽어보도록 하자...
그런데 사실 비즈니스 의사결정을 하는 사람들에게 이렇게 분포를 보여주는 것보다는 요약 통계량을 보고 빠르게 판단하게 함이 중요하다.
그래서 최소한 평균, 중앙값, 분산, 분위수(Quantile) -> 상위/하위 n% 값이 얼마인지. 4개의 정보를 제공하는게 중요하다. 1차원 데이터에서 4개의 정보를 제시하는 경우인데, 이렇게 4가지를 제시했을 때 손실되는 정보의 양은 어느정도인지 누군가 측정해줬으면 좋겠다. 그렇지만 통계학 관련해서 커뮤니케이션 하는 조직이나 대학원, 연구집단에서는 분포에 대한 이야기가 무조건 포함되어야 한다!
ref: Kevin P. Murphy, Probabilistic Machine Learning: An introduction. MIT Press, 2022. problem.ai
'Machine Learning' 카테고리의 다른 글
| GAN (0) | 2023.01.06 |
|---|---|
| 이진분류 (0) | 2023.01.01 |
| Detecting Seasonality With Fourier (0) | 2022.12.19 |
| 크롤링 & 워드클라우드 (0) | 2022.12.18 |
| Time Series Forecasting (0) | 2022.11.26 |
